In the previous article, I showed how to speed up a query by 600 times. In this part, I’ll demonstrate how we can refine the earlier results to improve the query performance even more.
This is the query we examine further:

The current execution plan for the temp table based version is:
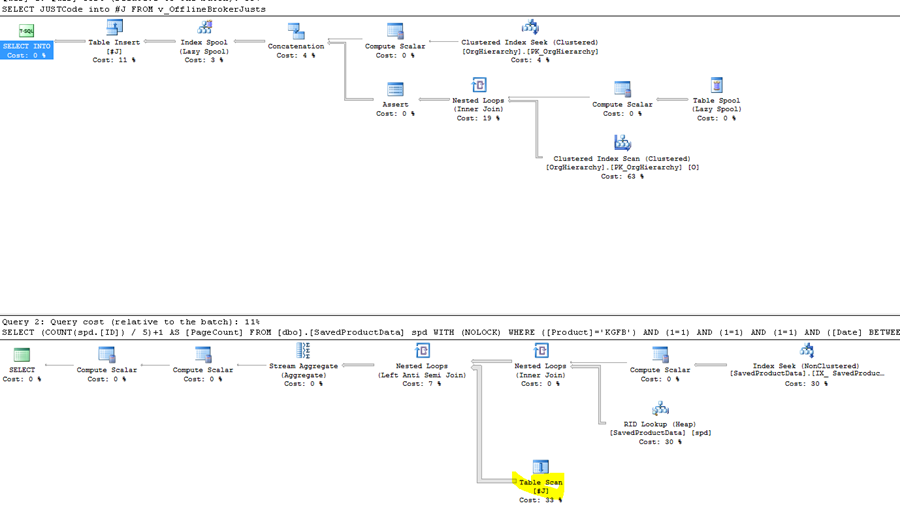
The upper plan fills the temp table. The lower plan is the filtered query which uses the temporal table created in the first step. The yellow Table Scan is ugly, mainly because it is on the inner side of a loop join. The knee-jerk reaction is to create an index to support this lookup:
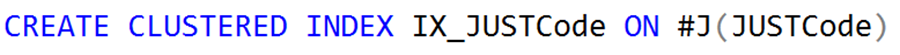
The execution time of the batch does not change; the IO on the #J table becomes twice because of the index creation. This is not a good direction to lower the execution time.
We have to realize that the query contains a NOT IN part. It is implemented as a Left Anti Semi Join. It is Left and Semi because we only need value from the left table (SavedProductionData). Anti, because we search for nonmatching rows. In short, we need rows from the SavedProductionData table, which has no corresponding row in the #J temp table. For EACH row, the server has to scan the entire #J table to know that it really does not contain any row in which JUSTCode is equal to the FirstJustCode of the outer table. This is the reason the index did not help. If the server has to read all rows from a table, an index does not help (in this particular scenario).
Ok, I could imagine a plan that tries to seek for at most one value which less than the probe value, and another to seek tries to find at most one value that is more than the probe value, and then if neither found a row, we know that there is no match. I don’t remember if I saw this approach chosen by SQL Server. It might not be implemented.
Ok, we have to come back from the fantasy world and try to kick out this slow scan operator. We can rewrite the NOT IN to NOT EXISTS if the following conditions are met:
- There is no NULL value in SavedProductionData.FirstJustCode column
- There is no NULL value in #J.JUSTCode
I checked the SavedProductionData.FirstJustCode column was defined as a NOT NULL column, but it did not contain NULL values. The developers could confirm my suspicion that this column should be defined as NOT NULL. Now I assume this is true.
I placed a UNIQUE constraint to the temp table, so I was sure it did not contain null (for my tested scenario).
“The most important thing to note about NOT EXISTS and NOT IN is that, unlike EXISTS and IN, they are not equivalent in all cases. Specifically, when NULLs are involved they will return different results. To be totally specific, when the subquery returns even one null, NOT IN will not match any rows.”
A performance-wise treatment of the topic is in this article.
Ok, back to our case. We can replace NOT IN with NOT EXISTS. Let’s compare the queries and their plans:
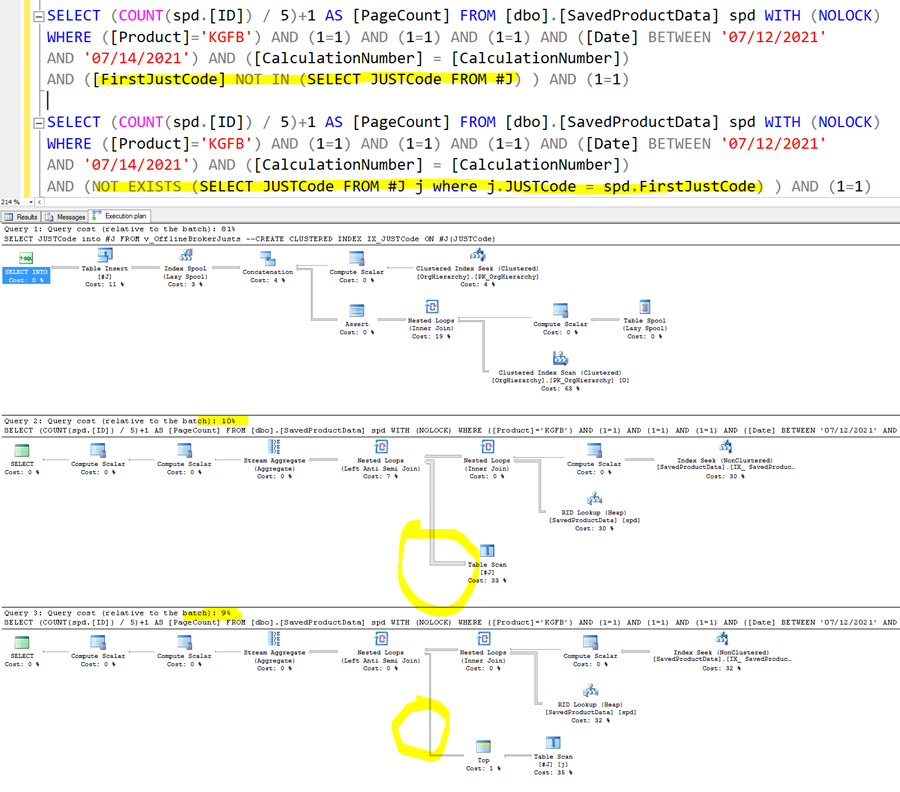
We see a difference in the thickness of the arrows coming from the scan; this is a good sign.
The actual duration confirms our warm feelings:

The NOT EXISTS version is two times faster! Good progress.
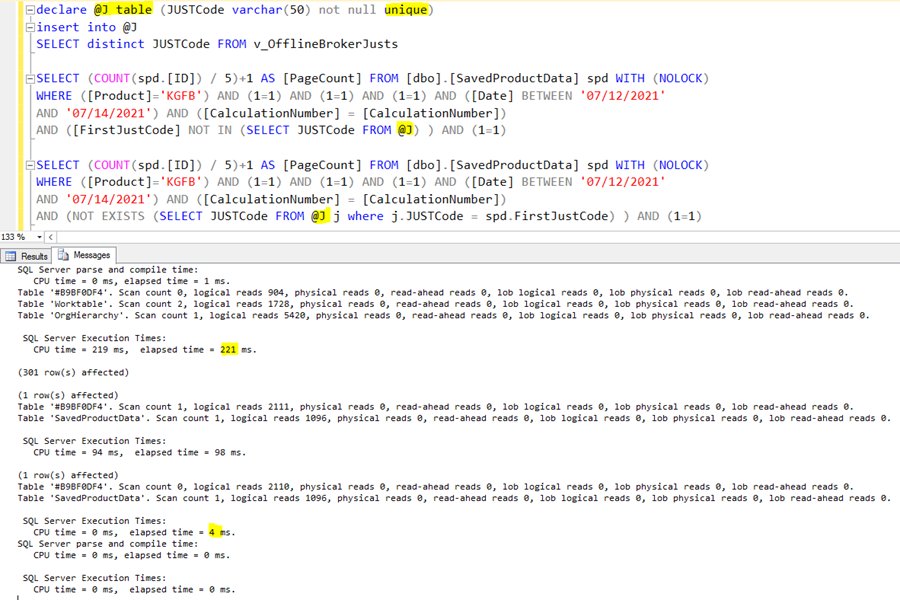
Now, we can reevaluate index usage on the temp table. To prevent duplicate rows in the temp table, I added a distinct to the query which fills the temp table. And I added the index creation statement back.
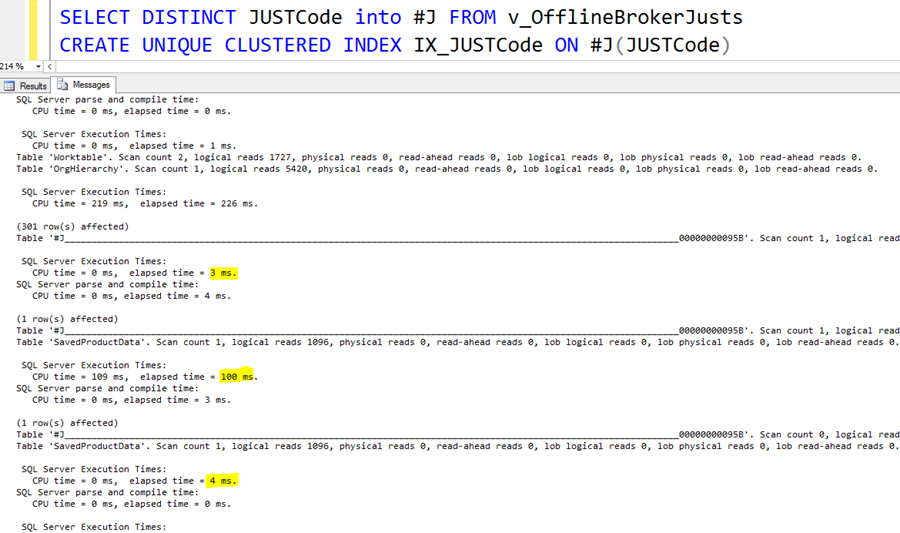
Wow, the execution time of the NOT IN version becomes 4ms! We started with 100ms in this iteration, which is a vast gain.
We probably cannot optimize this query much more, so we must focus on the temp table part. The temp table itself is created as a part of the select. So, we don’t know the table creation time because it is in the select duration. The index creation on the temp table needs 3ms time (upper yellow number), and an additional 4ms compilation cost is below it. This is expected because a DDL-DML transition introduces a recompilation.
We can avoid the DDL-DML reoptimization cost by using a table variable instead of a temp table:
The table variable creation time is not visible in the picture (I cut it, unfortunately, when I took the snapshot). There is no recompilation cost. The table variable contains the index we needed because I defined a unique constraint for it, so it can entirely replace the original temp table.
We can engage a bit with the “real” NOT EXISTS query because the query has one remaining costly operator, a RID Lookup:

We rarely see this operator in practice because it means there is no clustered index on the table. This is not a good practice for SQL Server. We can get rid (pun intended) of this RID lookup by an appropriate index. There is an almost good index; we have to add only one more column to it:

I used the SORT_IN_TEMPDB option because the database was part of an availability group, and I did not want to load the network with the index creation traffic.
Let’s test the performance of the query after the enhanced index:
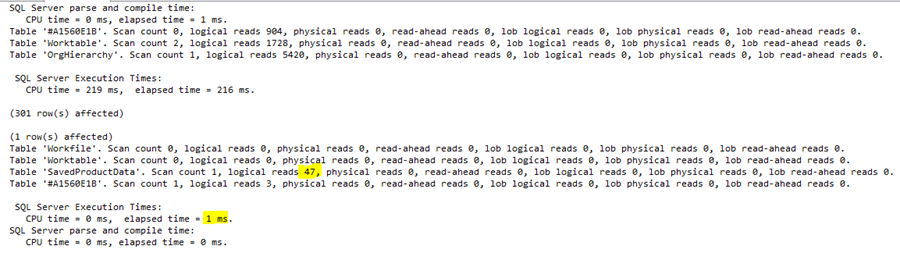
Well, the execution time of the NOT EXISTS query is 1ms. You read it well. It is 1ms. :)
The number of reads is 47; it was 1096 (check the earlier picture).
Ok, we are happy with this 1ms, but there is a 216ms temp table creation query that spoils the party.
Let’s try to optimize the temp table filler recursive query!
This is the query:
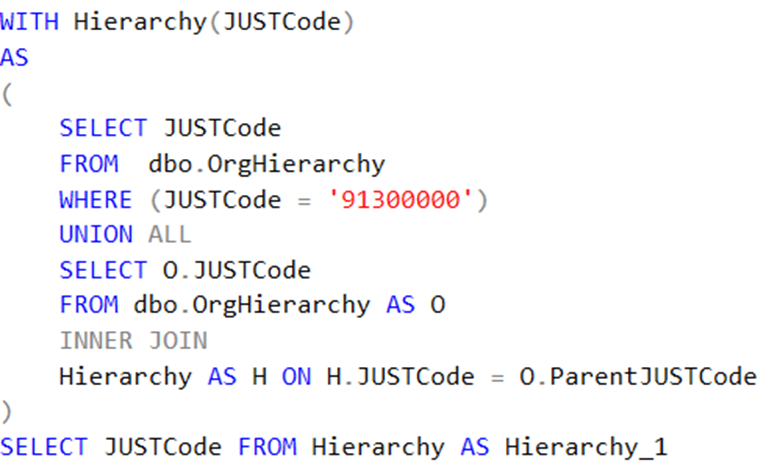
The execution plan contains an expensive scan operator on the OrgHiearchy table:
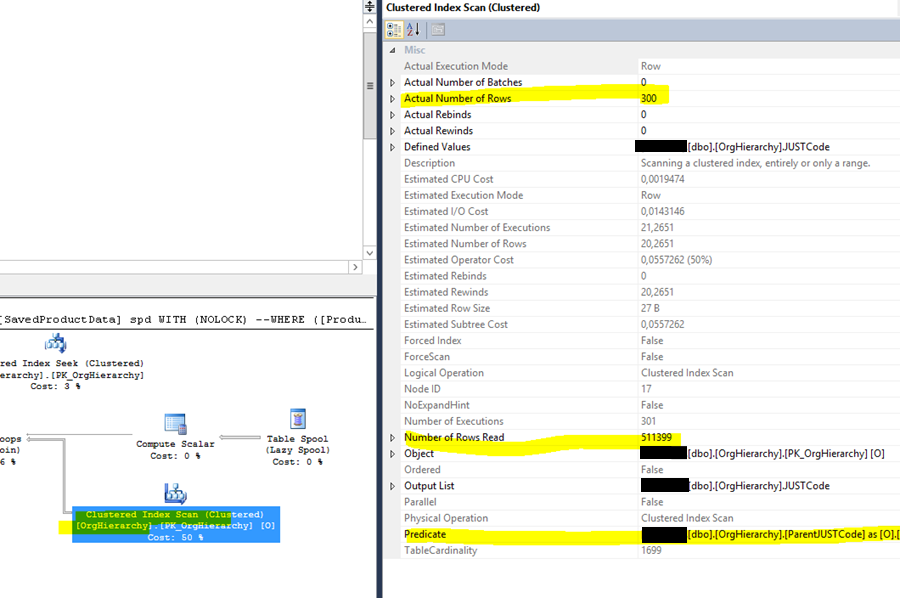
It yields 300 rows, but the server had to read 511399 rows to generate them. The 200ms execution time is totally justified.
We need a composite index on JUSTCode and ParentJUSTCode:
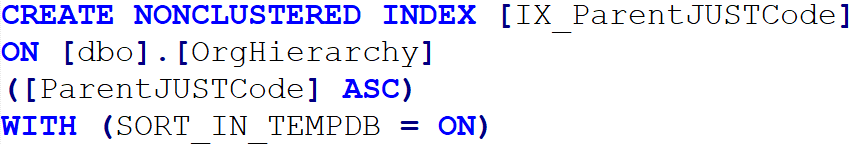
What’s interesting, I did NOT add JUSTCode to the index. It is the clustering key, so it will automatically be part of all nonclustered indexes.
The plan transforms into this:

There is a very handsome lookup instead of the original, ugly scan. Here are the performance numbers:
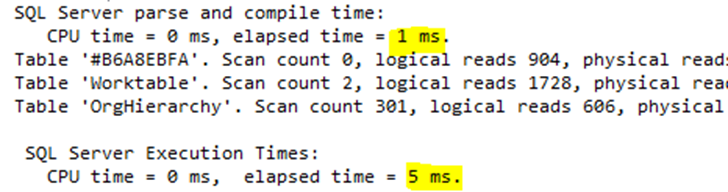
Oh my gosh, the original 219ms execution time becomes 6ms!
Let’s put together the whole batch:
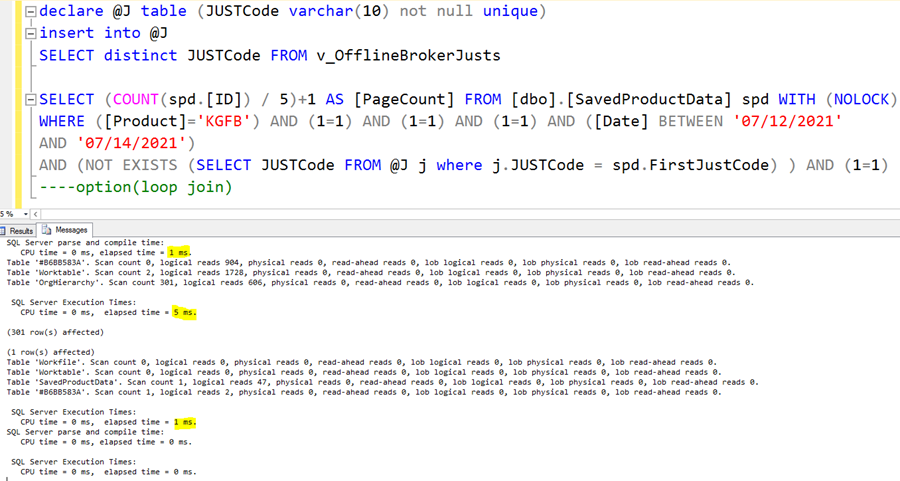
The duration of declaring the table is 1ms, the recursive query which fills it is 5ms, and the final query is 1ms. The total execution time is 1+5+1=7ms. We started with 255000ms.
This is a 255000/7=36428 times gain!
This is an exceptional gain, more than I promised in the first part of the article. But there is more! It can be slashed to 5ms. It is not a big difference anymore, but there will be exciting conclusions worth examining. I will write about them in the final, 3rd part of the article.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.