I wrote about a build pipeline recently. It is a multi-job DevOps server pipeline that runs integration tests in parallel. I wrote about it here. Each job had its database for isolated (integration) tests. The database size was 90GB for each one which prevented me from creating even more jobs to make the degree of parallelism greater.
I wanted to compress the largest tables and views in the database to make the database files smaller. Here are the two main disk hogs:

The second one is a big table; the first one is a view on the top of the table. You can see the total size of the view is 30 GB, and the table size is 20GB.
You can compress rows both in a table and an indexed view. You can read the details about data compression here.
You can choose ROW and PAGE compression. Row compression is faster, but page compression compacts data more but requires more CPU. My preference was the smaller database size and not CPU usage, so I tested PAGE compression only.
You can see the table size went from 19.9 GB to 7.2GB. The view was compressed from 30.4 GB to 9.6GB. Nice gain for both.

I was curious whether I could gain more by applying clustered columnstore index. I have tested the “normal” compression, not the more effective but much slower columnstore archive compression.
The catch here is that the columnstore index is not really an index. Therefore, I could not replace the original clustered primary key with a columnstore index. I had to create the columnstore index to contain the data, and after that, I had to create a new nonclustered (rowstore) index for the primary key on the top of the columnstore index. That means primary key-based lookups will be less efficient. Do not forget I optimized for size and not for performance; therefore, I can live with it.
Here is the result of the compression of the table with columnstore index:

These results are interesting. The data size (the actual table) by using columnstore compression is 1.1GB. Lovely reduction from the original 6.9 GB. For comparison, PAGE compression reduced data size to 2.4 GB, so columnstore is clearly a winner in this regard.
But, I had to create one more index on the table for the columnstore scenario because I needed the primary key constraint on the table. The new index made the sum of the index size 9 GB. The original indexes using PAGE compression took 4.8 GB only. So, the final total numbers are 7.2GB vs. 10GB; simple PAGE compression won.
So, when choosing a compression scheme, consider the overhead of a new index when you want to use a columnstore index.
Update
The columnstore results were worse than I had expected. Therefore, I double-checked the indexes. I was afraid I did not turn on data compression on the new clustered index or the NC indexes. But I did turn it on, confirmed.
To make it more understandable, here is the data usage for each index for the columnstore scenario:
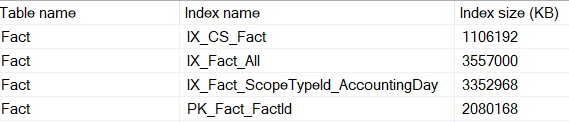
We can verify that the size of the columnstore index is indeed 1.1GB. The PK_Fact_FactId index is the new index behind the primary key. We expected 2GB more index space compared to the PAGE compressed table. However, we saw 7.2GB vs. 10GB, which is 1.2GB more than we anticipated. Why?
Let’s query index sizes for the PAGE compressed version!

The primary key is a clustered index that contains the entire table; hence, it is expected to be a bit larger in this case.
But -and this is not trivial- there is a significant increase in the size of the nonclustered indexes! 2.47 vs. 3.56 GB. And 2.35 vs. 3.35GB. Why? I tripe-checked, and they are PAGE compressed. A nonclustered index size increases when the clustering key or the row pointer at leaf level becomes larger.
The original clustered index key was 4 bytes. Because it was a unique index, no other 4 bytes were used by the server to force uniqueness.
When the NC index is built on a CLU columnstore index, an 8 bytes row locator is used. We have 188495195 rows, which means we expect the NC index to be 188495195 * 4 bytes = 736309 kB larger than the original one. The actual difference for IX_Fact_All is 3557-2366 = 1091MB. The calculated difference is close to the measured one but not accurate.
For IX_Fact_ScopeTypeId_AccountingDay the difference is 3352-2351=1001MB. The overhead is not exactly 4 bytes, but a bit more.
Using this script from the linked StackOverflow post, we can check the actual row sizes:
SELECT
DDIPS.index_level,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.min_record_size_in_bytes,
DDIPS.max_record_size_in_bytes,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'TIMEDATABASE.Fact', N'U'),
INDEXPROPERTY(OBJECT_ID(N'TIMEDATABASE.Fact', N'U'), N'IX_Fact_All', 'IndexID'),
NULL, 'DETAILED'
) AS DDIPS;


The leaf (0) level is the most interesting to examine because it is the bulk of the index size. Columnstore CLU index-based NC index has a 16.3 bytes average row size. Rowstore CLU index-based NC index has a 10.6 bytes average row size. Now we can see that the actual overhead is not 4 bytes, but barely 6 bytes when we use columnstore CLU index instead of row-store int CLU index.
So did my conclusion to use simple PAGE compression instead of columnstore compression change? No, it did not. In this particular scenario, PAGE compression is better. But it was interesting to play with the two compression methods.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.
LEAVE A COMMENT
1 COMMENTS