The issue described in this article was one of my most challenging cases. I solved it with my client in 2017.
The architecture is simple. ASP.NET pages call internal Web Services. The web services use SQL Server for data storage.
The client had an excellent monitoring system. They used DynaTrace, a unique profiler capable of merging the internal timing of the code from multiple servers. I.e., you can see the duration of the called methods on the ASP.NET page; then you can see the elapsed time of the network communication, and afterward, the duration of the method calls inside the web service on another machine.
Here is a such a merged stack trace:

The ExecuteReader takes place on the Web Server, then a network communication to the Web Service, and the ValidateUser method runs on the Web Service.
There were constant delays in the order of 200ms during the network roundtrip of the web server and the web service.
The actual response time of the web service was 1-10 ms. We could not find a reasonable explanation for the 200ms delay for each call.
We thought about the DNS issue, but it was ruled out because the Web Service client used an IP address instead of a name.
I spent two days analyzing the network communication with WireShark and correlating it with DynaTrace logs. And after a while, I could plot the round trip time between the web app and the web service. Here is it:
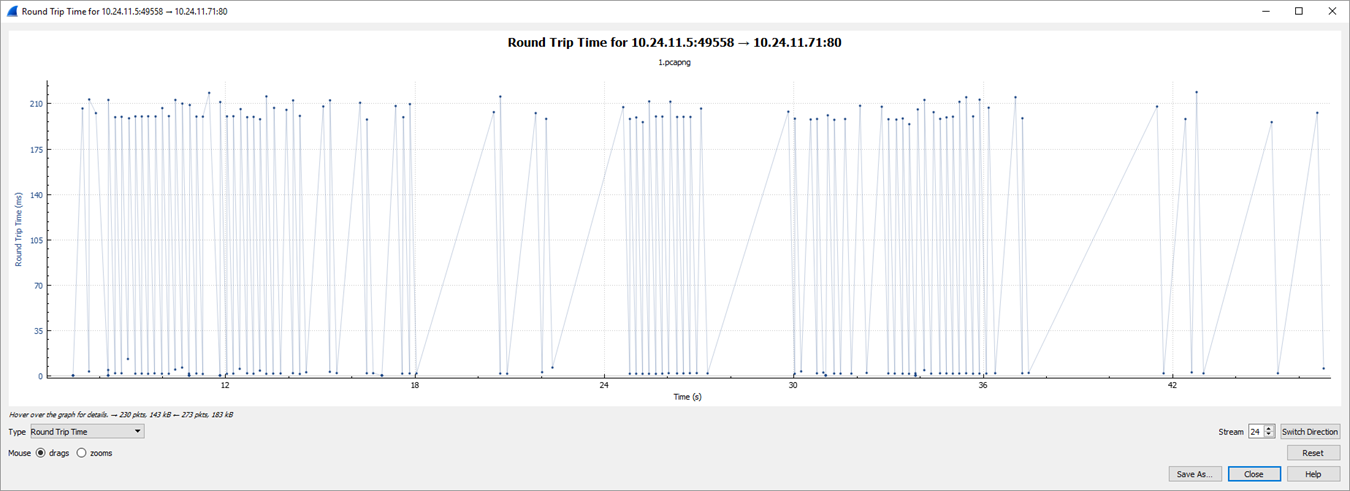
You can see lots of requests has a 200ms roundtrip time. Some of them are very fast (dots near the X-axis), which is the expected result.
Here is what the maximum values of the RoundTrips look like. In some short time segments, the mysterious delay disappeared, but most of the time, it prevailed.
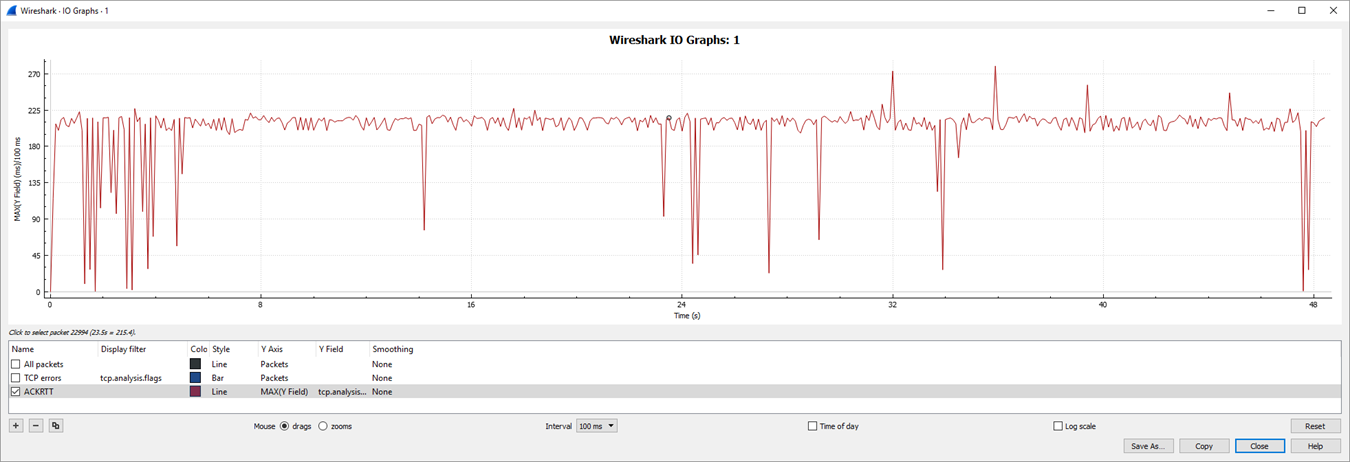
Then I filtered for packets which has more than 100ms roundtrip time:
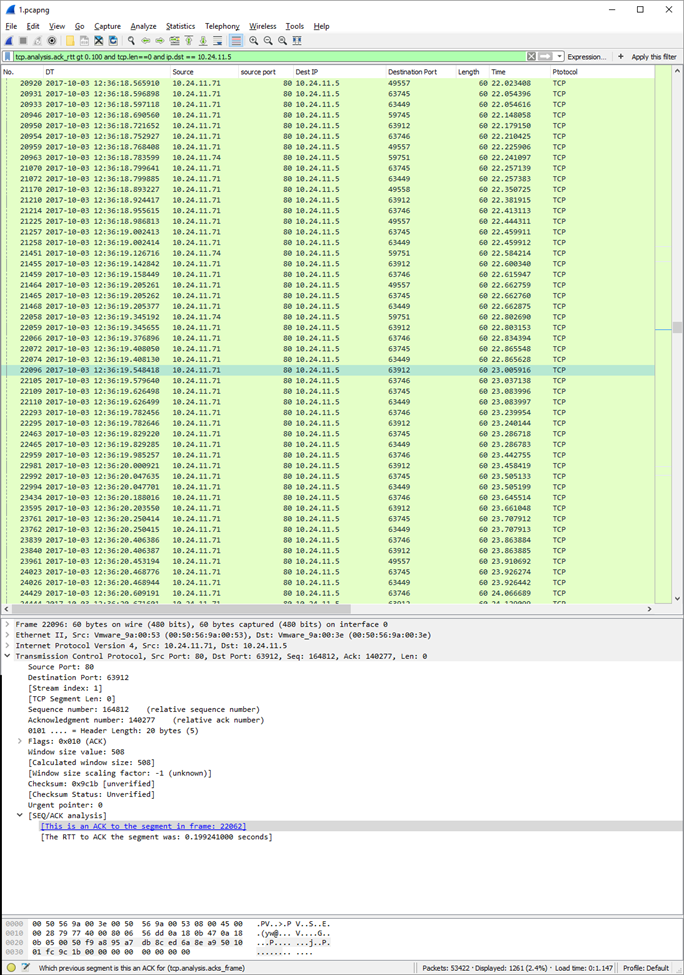
I correlated the delayed packets in WireShark with the logs in DynaTrace. It was apparent that the ACK (TCP Acknowledge) arrived 200ms after the packet was sent from one of the computers.
I found an article that described a similar delay. I won’t rehearse what you can read there. Just write the central tenets shortly.
There are two internal network technologies here.
“The Nagle algorithm (by John Nagle) is a method for congestion control (RFC 896), so the sender won’t flood the receiver with data. When the sender sends a packet to the receiver, the sender will wait for an ACK from the receiver before sending the following packets.”
Naggling was turned off; it can be controlled from the .NET API. You can see it as Push=1 in WireShark.
“The delayed ACK algorithm is also a method for congestion control (RFC 2581), so the receiver won’t flood the network with ACK packets. When the receiver has to send an ACK in response to a packet, it waits for a little (200 ms or until it has two outstanding ACKs) to see if more packets should arrive that it can acknowledge with that single ACK.”
(You can watch a deep analysis of the interaction between Nagle and Delayed Ack here. It is a fascinating video. Things are much more complicated than you might think.)
When A sends a packet to B, B has to acknowledge it. To conserve bandwidth, B does not send the Ack immediately, but it waits for another packet sent from B to A and piggybacks the Ack to that packet. In the (very improbable) case, there is no packet from B to A. It sends the Ack after 200ms. It is better late than never. In our case, there was a constant flow of packets between the machines, so B had many chances to send the Ack back. But it did not.
The other scenario is that B waits till it has two acks to send back and sends them together. But if A does not send the 2nd packet till B acknowledges it, then B sends the Ack back in 200ms, so A waited for B. This is similar to a deadlock which is resolved by a timer event.
A similar situation arises when A sends such a small request that it is fit into a single packet. There won’t be a second packet for the double acknowledge. Anyway, our scenario involved such small requests.)
To prove my hypothesis (web service is lazy to send Ack), I filtered the packets with no payload, just the ack info, and more delay than 0.1ms. You can find them in WireShartk by filtering for tcp.len=0 and tcp.analysis.ack_rtt gt 0.10:
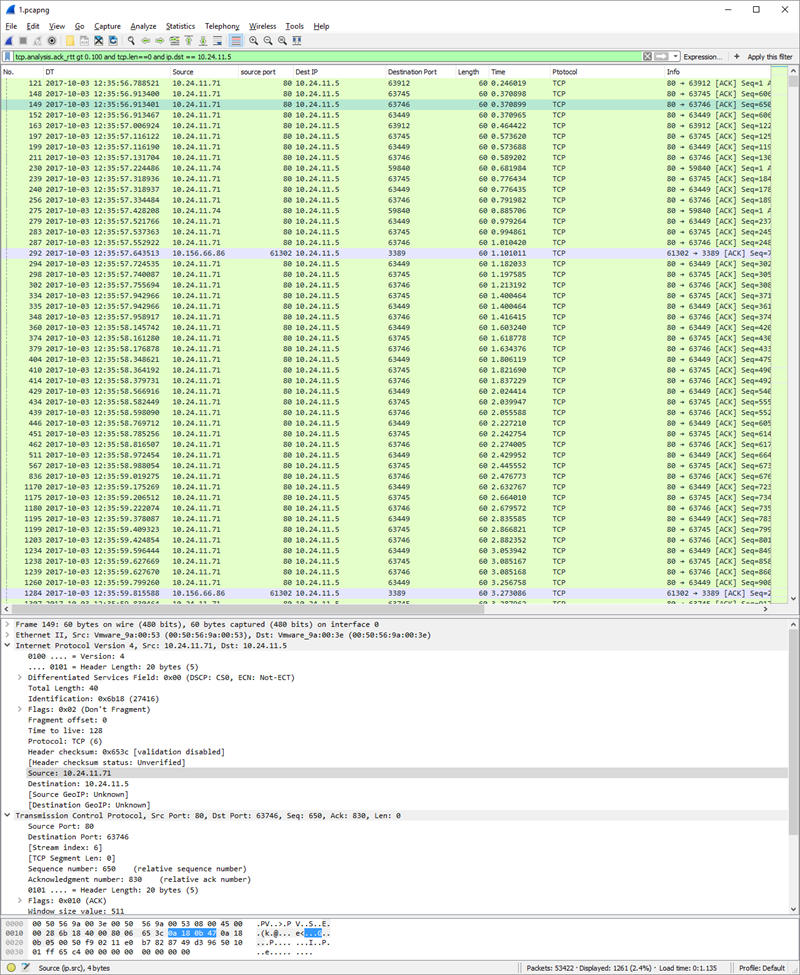
There were many pure ack transmitter packets from the Web Service to the Web Server than in the other direction. The Web Server sent a packet to the Web Service that contained the web request payload. The Web Service acknowledged that packet 200ms later, not as soon as it could (within some micro sec).
Why? It was probably a bug in the network card driver (VMWare).
As a mitigation, we turned off the delayed Ack on the Web Service machine by setting the TcpAckFrequency registry setting to 1.
“TcpAckFrequency is a registry entry that determines the number of TCP acknowledgments (ACKs) that will be outstanding before the delayed ACK timer is ignored.
…
If you set the value to 1, every packet is acknowledged immediately because there’s only one outstanding TCP ACK as a segment is just received.”
Non-delayed Ack naturally means more traffic on the network. But we had virtual network cards, and the live traffic was 1/100 of the available network bandwidth. So, the more frequent Ack was a small price to decrease the 200ms delay to almost 0. The reduced delay was some micro sec, four orders of magnitude faster.
For comparison, the response time of the 2-5 web servers (turned on and off during the week) for each day. Green: 0-4 sec; Orange: 4-10 sec; Red: more than 10 sec
These results are before implementing the mitigation. On Tuesday afternoon, the Web Site started to show a significant delay. The company spawned new servers, but all of them experienced delays.
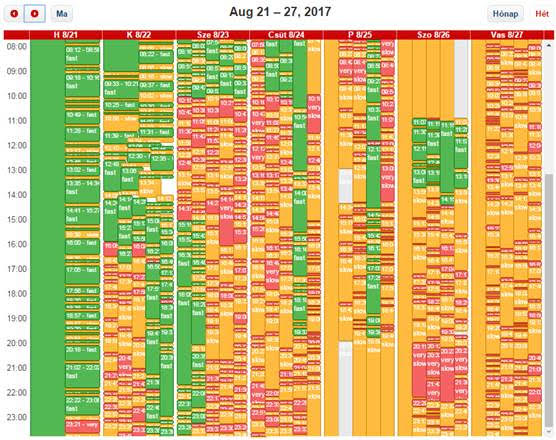
You can see the system was in terrible shape.
After disabling delayed Ack, we saw this picture:
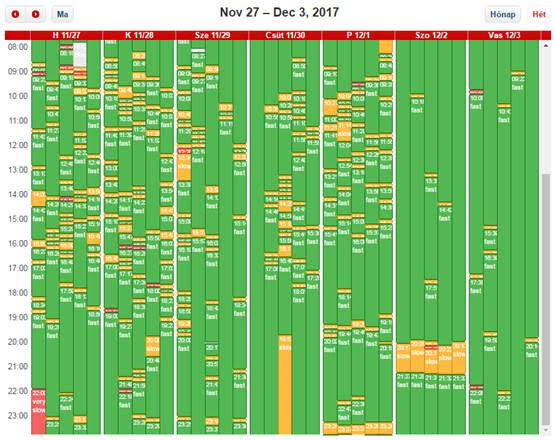
The difference is day and night. :)
Moral of the story: it is good if you try to find a bug in your code first, but do not rule out external bugs. After all, that system’s programmers are just human programmers like you.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.