Az előző rész indexére alapozva nézzünk meg két lekérdezést, hogyan tudja támogatni a hash index.
Először egy pontszerű lekérdezés, egyenlő operátorral:
select * from Person.Person_InMem where ModifiedDate = '20120112'
Végrehajtási terv:
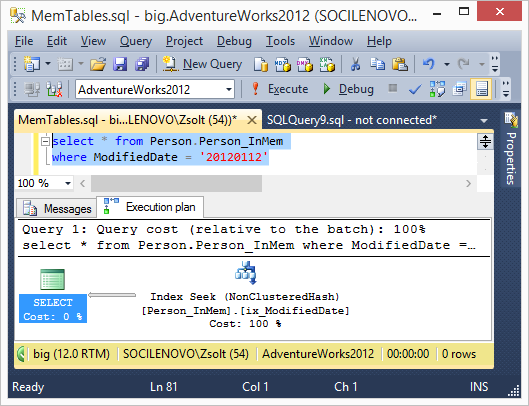
Szépen használja az indexet, seekel.
Kisebb operátor esetén:
select * from Person.Person_InMem where ModifiedDate < '20120112'
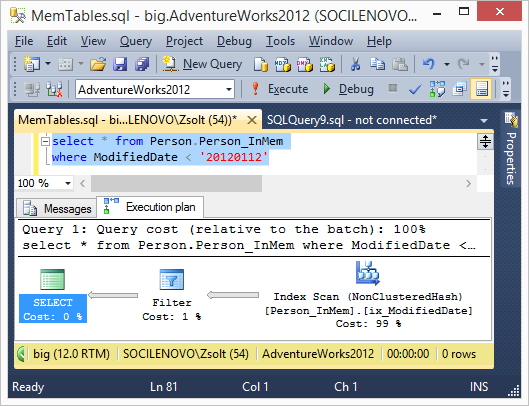
Kénytelen végignézni az összes sort, mivel a hash indexekkel nem lehet csak egyenlőségre keresni, ezért a scan operátor a tervben.
Az összetett hash indexek nem használhatók kevesebb oszlopra szűrésre, még akkor sem, ha az első oszlopokból válogatunk. Azaz egy FirstName, LastName összetett hash index csak egyszerre erre a két oszlopra képes seekelve szűrni, csak a FirstName-re nem, mivel a hash a két értékre együtt került kiszámítása, külön nem értelmezhető.
Hogyan tárolja a szerver a hash indexeket?
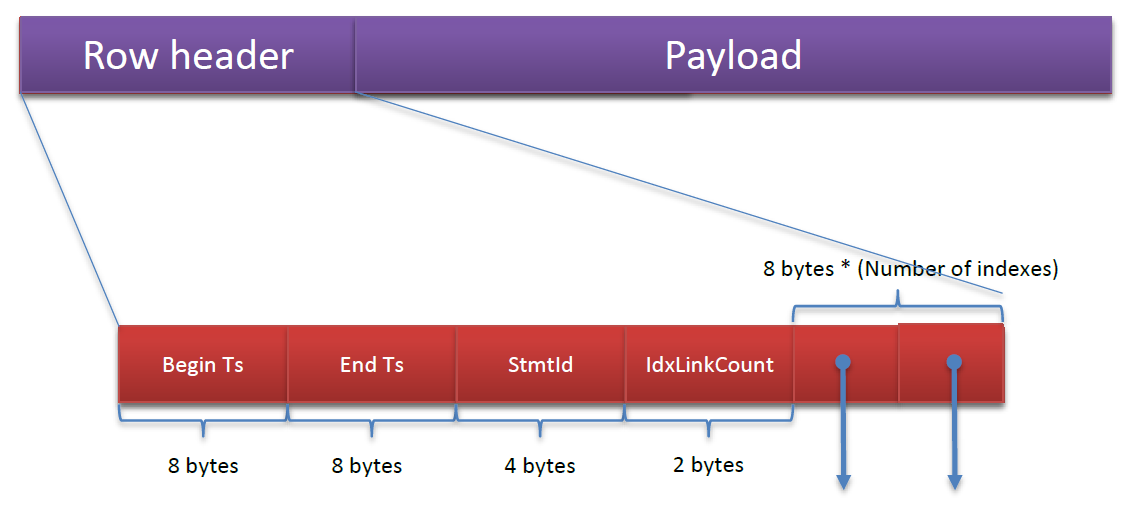
Az ábrából látszik, hogy minden sor tartalmaz n * 8 byte-os pointert, minden egyes ilyen pointer egy indexehez tartozik.
A hash függvény alapján kiadódik egy hash érték, ezzel beleindexelnek a hash indexbe, ami egy sima lineáris tömb. A tömb adott eleme azaz egy vödre rámutat egy sorra. De mivel több sornak is lehet azonos a hash-e az adott index kulcsa alapján, ezeket láncolják hozzá az előző sorhoz az index pointeren keresztül. Nézzük ezt meg egy ábrán:
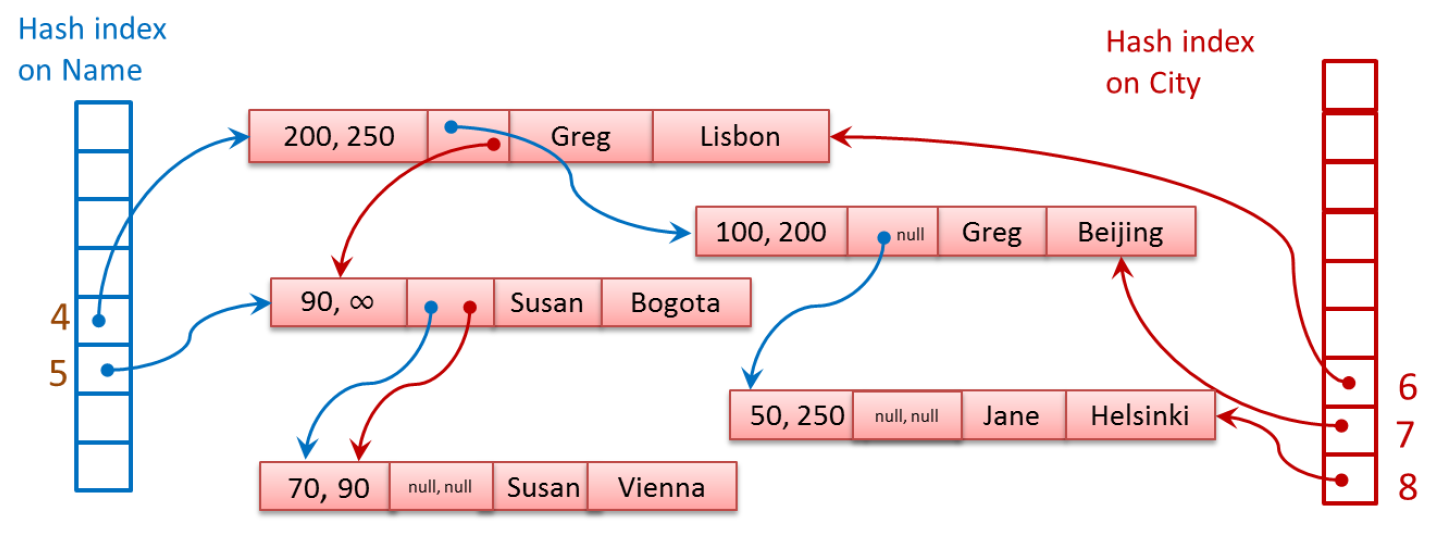
A bogotai Susannak és a bécsi Susannak is ugyanaz a hash-e, hisz azonos az értékük. Az 5-ös vödör rámutat az egyik sorra, majd onnan a sorból az első index mutató keresztül lehet továbbmenni a következő sorra (láncolt lista).
A 4-es Name hash esetén a két Gregnek és Jane-nek azonos a hashe, azért ők hárman lesznek összeláncolva.
A City oszlopon létrehozott hash index 6-ot rendelt hozzá Liszabonhoz, Bogotához és Bécshez is, ezért ők hárman vannak összeláncolva.
Az ábrából látható, hogy a hash indexek nagyon hatékonyak, ha rövid a láncolt listájuk, de mi a helyzet a módosítással? Miért nem akadnak össze a szálak, amikor pl. törölnek egy sort a láncolt listából? Hogyan oldják ezt meg lock nélkül?
Minden műveletet a korábban már említett Compare Exchange-zsel oldanak meg. Ez egy 3 argumentumú művelet, a .NET doksiból:
public static T CompareExchange<T>( ref T location1, T value, T comparand )
Összehasonlítja a location1-et a comparanddal, és ha egyeznek, akkor value-t belerakja location1-be. A visszatérési érték a location1 eredeti értéke, ez azért kell, hogy tudjuk, sikerül-e berakni value-t location1-be. Mindezt atomi módon, a processzor támogatásával végzi a gép.
A következő rész natív spekuláció, doksiban nem láttam kirészletezve.
Tegyük fel két versengő folyamat is be akar szúrni egy-egy sort úgy, hogy mindkét sor ugyanabba a vödörbe esik. Tegyük fel a vödörben már van egy sor. Akkor ennek a sornak a következő sorra mutató pointere null lesz.
Bejön az első folyamat. Létrehozza az új sort a levegőben. Ránavigál a hash index vödörből az első sorra, majd végrehajt kb. egy ilyen kódot:
CompareExchange(ref első sor következő pointere, a beszúrandó sor címe, null)
Ha ez a folyamat volt a gyorsabb, akkor az első sor következő pointerét nullként látta, tehát ő tudja hozzárendelni a sorát a next pointerbe, ő tudta magát beláncolni a sorba.
A lassabb folyamatnak már nem nullt lát localtion1-ben, azaz az első sor next pointerében, ezt észreveszi abból, hogy a CompareExchange visszatérési értéke nem null. Ilyenkor mit kell tennie? Ránavigálni a következő (a másik által az előbb beszúrt sorra), és ott újra bepróbálkozni. Előbb-utóbb csak ő is első lesz.
Miért nagyon gyors ez a folyamat? Mert egyáltalán nincs zárolás nem hogy nagyobb felbontással, lap szinten, de még sor szinten sem.
A törlések kezelése már macerásabb lenne, ha így akarnák megoldani. Csakhogy a törlések teljesen másképp mennek, mivel a snapshot izolációs szint miatt meg kell tartani a sor korábbi verzióját is, nem lehet csak úgy kitörölni. Ennek megvalósításáról is lesz szó a párhuzamosságról szóló részben, de előtte még megnézzük a normál indexek hogyan működnek, a következő részben.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.