Lássunk most egy olyan lekérdezést, amiben nem annyira fényes a HierarcyID.
Szeretném lekérdezni a közvetlen beosztottakat, azaz egy node első szintű gyerekeit, az indirekt utódok nem érdekelnek. Ehhez egy új metódust vetünk be, a GetAncestort, melynek paramétere a kívánt szintű előd, esetünkben 1, mert a közvetlen szülő érdekel:
declare @manager hierarchyid = (select OrgNode from HumanResources.NewOrg where LoginID = 'adventure-works\roberto0') select @manager.ToString() select cast(OrgNode as varchar(50)) as OrdPath, EmployeeID, LoginID, ManagerID, Title from HumanResources.NewOrg where OrgNode.GetAncestor(1) = @manager
Kimenet:
------------------------------ /2/1/ OrdPath EmployeeID LoginID ManagerID Title ------------------------------ ----------- ------------------------------ ----------- ------------------------------ /2/1/1/ 4 adventure-works\rob0 3 Senior Tool Designer /2/1/2/ 9 adventure-works\gail0 3 Design Engineer /2/1/3/ 11 adventure-works\jossef0 3 Design Engineer /2/1/4/ 158 adventure-works\dylan0 3 Research and Development Manag /2/1/5/ 263 adventure-works\ovidiu0 3 Senior Tool Designer /2/1/6/ 267 adventure-works\michael8 3 Senior Design Engineer /2/1/7/ 270 adventure-works\sharon0 3 Design Engineer
Szemre jónak néz ki a kimenet, csak az első szintű utódok jöttek le. Lássuk a végrehajtási tervet:

Látható, hogy a HierarchyID alapján már nem képes csak index seek-kel leválogatni a tartalmat, mert azzal csak az összes utódot tudja megszűrni, nekünk meg csak a közvetlen utódok kellenek. Ezért van ott a Filter operátor, ő az összes utódból leválogatja a kért szinten levőket.
Hogy ez mennyire nem hatékony úgy buktatható le, ha keresünk egy olyan embert, akinek nagyon sok idirekt beosztottja van, de csak kevés közvetlen. Nyilván a fa tetején ülnek ezek, nézzünk csak egy kis statisztikát:
select LoginID, OrgNode.ToString() as Path, (select COUNT(*) c from HumanResources.NewOrg i where o.OrgNode.IsDescendant(i.OrgNode) = 1) as TotalNumberOfDescedants from HumanResources.NewOrg o order by TotalNumberOfDescedants desc
Futtatva:
LoginID Path TotalNumberOfDescedants ------------------------------ ------------------------------ ----------------------- adventure-works\ken0 / 290 adventure-works\james1 /5/ 209 adventure-works\peter0 /5/1/ 185 adventure-works\laura1 /4/ 29 adventure-works\brian3 /6/ 18 adventure-works\jack0 /5/1/19/ 14 adventure-works\terri0 /2/ 14 ...
Ken0 a nagykutya, futtassuk le vele a kiinduló lekérdezést, és nézzük meg a tényleges (nem jósolt) végrehajtási tervet:

Látható, hogy vastag nyíl jön ki az index seekből, 290 sort válogat le az index, ami nem meglepő az előző táblázat alapján. A Filter ebből csak 6-ot tart meg. Tulajdonképpen bár index seek az operátor, a teljes táblát végignyalta (table scan), ennek megfelelően az IO költsége 9 lapolvasás, ekkora a tábla (ha precíz akarok lenni, a tábla 7 lapból áll, plusz 2 IO másra megy el).
Vessük ezt össze a relációs lekérdezéssel, ami triviális lesz:
declare @ManagerID int = ( select EmployeeID from HumanResources.NewOrg where LoginID = 'adventure-works\ken0') select * from HumanResources.NewOrg where ManagerID = @ManagerID
Ez pusztán 2 lapolvasással jár (csak a 2. select, az elsőt a méréseknél nem veszem figyelembe), jó, épít az előző részben felépített cover indexre. A végrehajtási terv pusztán egy index seekből áll, azért ilyen piszok hatékony.
Összegezve, direkt gyermekek lekérdezése esetén a relációs megoldás általában gyorsabb, mint a HierarchyID alapú. Persze, azért denormalizálással lehet még itt alakítani.
A HierarchyID indexe a következő sorrendben rendezi be az adatokat (BOL-ból lopva):
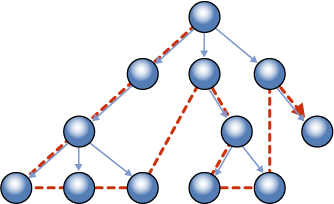
Ami nekünk kellene a direkt gyerekek hatékony szűréséhez, az a szélességi bejárás alapján rendezett index:
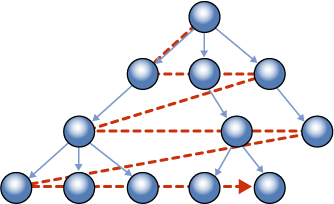
Készítsünk ilyet! Ehhez fel kell vennünk a táblába egy új, számított oszlopot, ami a node-ok szintjét számolja ki (GetLevel metódus):
alter table HumanResources.NewOrg add OrgLevel as OrgNode.GetLevel()
Csak, hogy lássuk, hogy is néz ez ki:
select OrgNode.ToString(), OrgLevel, * from HumanResources.NewOrg order by OrgNode
Path OrgLevel EmployeeId ManagerID ------------------------------ -------- ----------- ----------- / 0 109 NULL /1/ 1 6 109 /1/1/ 2 2 6 /1/2/ 2 46 6 /1/3/ 2 106 6 /1/4/ 2 119 6 /1/5/ 2 203 6 /1/6/ 2 269 6 /1/7/ 2 271 6 /1/8/ 2 272 6 /2/ 1 12 109 /2/1/ 2 3 12 /2/1/1/ 3 4 3 /2/1/2/ 3 9 3 /2/1/3/ 3 11 3 /2/1/4/ 3 158 3 /2/1/4/1/ 4 79 158
No, most jön az index a számított oszlopra:
create nonclustered index IDX_Org_Breadth_First ON HumanResources.NewOrg(OrgLevel, OrgNode) include (EmployeeID, LoginID, ManagerID, Title);
Megint egy bazi nagy index, nem biztos, hogy kell ennyi oszlop az include részbe, de így lefedtük a *-os lekérdezéseket is.
A kiinduló lekérdezés (ken0-val) végrehajtási terve alaposan megváltozik:

Állat, mi? Sima index seek lett, ráharapott az újdonsült indexünkre! Fel van arra készítve az optimizer, hogy a GetAncestor-t hatékonyan tudja végrehajtani, ha meg van támogatva egy jó kis breadth-first index-szel.
Amúgy 2 lapolvasásból áll így a lekérdezés, az eredeti 8 helyett. Mondanom sem kell, a poén az, hogy ha a tábla mondjuk 2%-a jön le a lekérdezés hatására, akkor ez az optimalizált verzió csak a tábla ötvenedét járja be, míg az eredeti az egészet! Nagy fák esetén ez brutális különbséget jelent, nem csak négyszereset, mint a példámban.
A témáról bővebben a BOL-ban lehet olvasni.
Ebben kielemzik a HierarchyID vs. rekurzív vs. xml lehetőségeket, ezt egyelőre nem részletezem tovább, annyi sok más újdonságról akarok még írni.
A következő részben még egyszer játszunk a HierarchyID-vel, nem csak lekérdezzük, de módosítjuk is a fát.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.