Ha egy nullos oszlopon szűrünk, akkor előfordulhat, hogy a bemeneti paraméter is null.
where oszlop = @param
Ebben az esetben az SQL Server alapban az ansi nullságot alkalmazza, így a null != nullal, azaz nem jön vissza egy sor se. Ezért EF6-ban az SQL generátor más sqlt generál, az ilyen esetekben egy IS NULL-os ággal megoldja, hogy nullokra is menjen a keresés.
Viszont ennek drámai mellékhatásai lehetnek. Lássunk egy egyszerű példát:
using (var e = new AdventureWorks2012Entities())
{
var matthew = "Matthew";
e.Person.FirstOrDefault(p => p.LastName == matthew);
}
Ez esik ki az EF-ből:
declare @p__linq__0 nvarchar(4000) = N'Matthew'
SELECT TOP (1)
[Extent1].[BusinessEntityID] AS [BusinessEntityID],
[Extent1].[PersonType] AS [PersonType],
[Extent1].[NameStyle] AS [NameStyle],
[Extent1].[Title] AS [Title],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[MiddleName] AS [MiddleName],
[Extent1].[LastName] AS [LastName],
[Extent1].[Suffix] AS [Suffix],
[Extent1].[EmailPromotion] AS [EmailPromotion],
[Extent1].[AdditionalContactInfo] AS [AdditionalContactInfo],
[Extent1].[Demographics] AS [Demographics],
[Extent1].[rowguid] AS [rowguid],
[Extent1].[ModifiedDate] AS [ModifiedDate]
FROM [Person].[Person] AS [Extent1]
WHERE (([Extent1].[LastName] = @p__linq__0)
AND ( NOT ([Extent1].[LastName] IS NULL OR @p__linq__0 IS NULL)))
OR (([Extent1].[LastName] IS NULL) AND (@p__linq__0 IS NULL))
Látható, hogy bool algebrával összehozták, hogy ha a paraméter null és az oszlop is null (is nullal), akkor lejönnek szépen a sorok. Viszont az ilyen query-ket utálja az sql server, nehezen tudja őket optimalizálni. option(recompile) segítene rajta, de ezt meg nem lehet kiadni EF-en keresztül.
Szerencsére vissza lehet állítani a régi kódgenerátort is:
using (var e = new AdventureWorks2012Entities())
{
e.Configuration.UseDatabaseNullSemantics = true;
var matthew = "Matthew";
e.Person.FirstOrDefault(p => p.LastName == matthew);
}
Generált SQL:
SELECT TOP (1)
[Extent1].[BusinessEntityID] AS [BusinessEntityID],
[Extent1].[PersonType] AS [PersonType],
[Extent1].[NameStyle] AS [NameStyle],
[Extent1].[Title] AS [Title],
[Extent1].[FirstName] AS [FirstName],
[Extent1].[MiddleName] AS [MiddleName],
[Extent1].[LastName] AS [LastName],
[Extent1].[Suffix] AS [Suffix],
[Extent1].[EmailPromotion] AS [EmailPromotion],
[Extent1].[AdditionalContactInfo] AS [AdditionalContactInfo],
[Extent1].[Demographics] AS [Demographics],
[Extent1].[rowguid] AS [rowguid],
[Extent1].[ModifiedDate] AS [ModifiedDate]
FROM [Person].[Person] AS [Extent1]
WHERE [Extent1].[LastName] = @p__linq__0
Így már egy teljesen tiszta szűrést kapunk, de ez NEM menne null bemeneti paraméterre. Ha nem is kell, hogy menjen, akkor viszont ez sokkal gyorsabb lehet, mint az első, megfelelő indexek esetén.
A két lekérdezés tervét egymás mellé rakva jól látható a különbség:
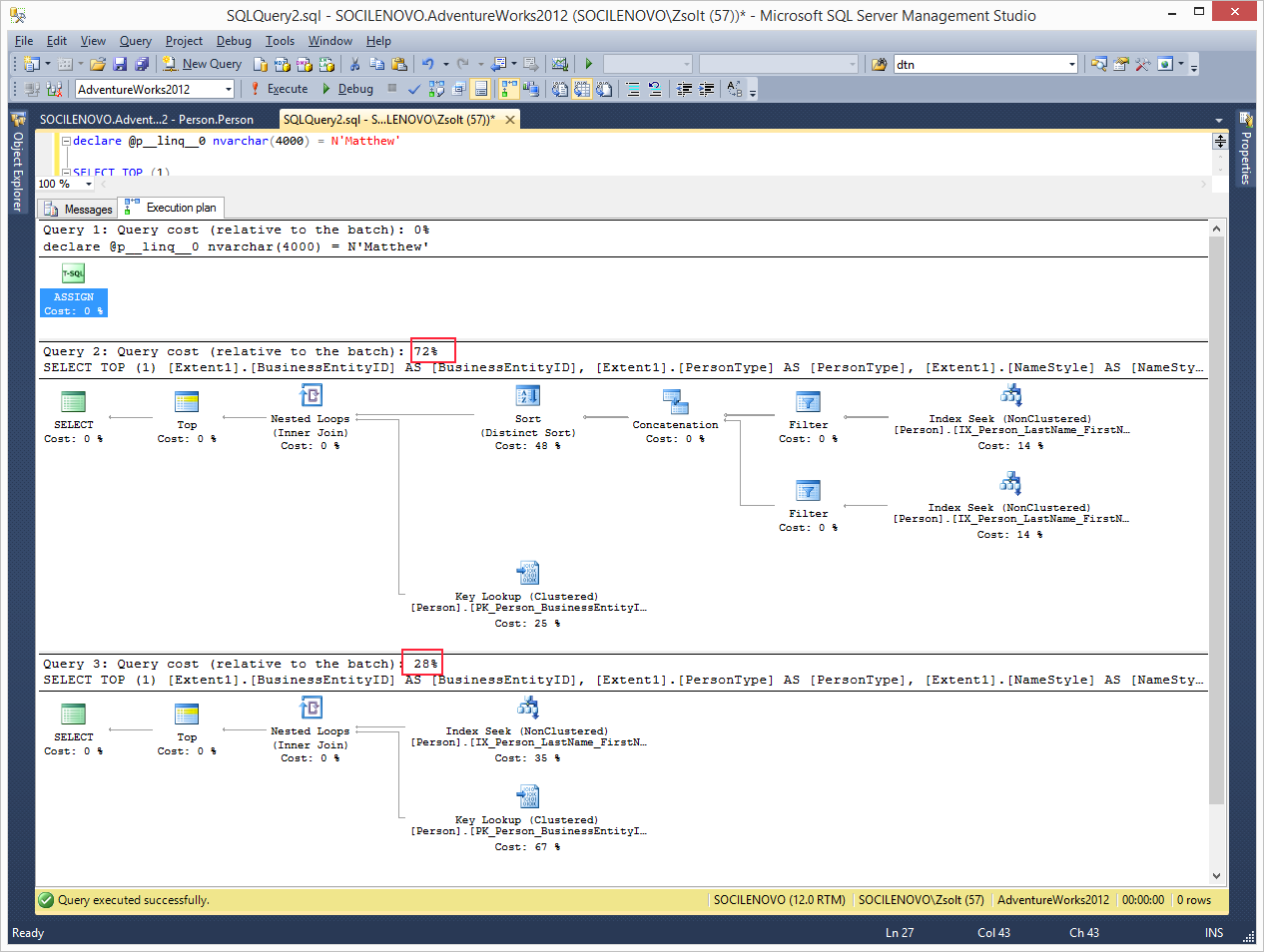
Nagyobb tábláknál a hatás sokkal radikálisabb lenne, érdemes szem előtt tartani ezt.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.
LEAVE A COMMENT
12 COMMENTS
Most tényleg, egyre kevésbé tűnik jó megoldásnak az ORM! Azt hisszük, hogy sokat spórolunk vele időben, de jó lenne egy tényleges összehasonlítás, mondjuk az SP-ben megvalósított megoldásokhoz képest, hogy mennyi a nyereség. Többféle megoldást láttam már eddig, a kódgenerálóstól kezdve a dinamikus típusig, vagy akár EF SP hívásai. Egy projektben összességében viszont nem tudom mennyire több minden szempontot figyelembe véve. A DTO objektumok és DB objektumok típuskonverzióját valamennyi megoldás jól tudja támogatni, viszont annak van egy “varázsa”, ha minden lekérdezésed ott van a DB-ben és nem a forráskódban, vagy nem generálódik röptében. Nem véletlen az se, hogy a nagy terhelésű rendszerek mind átállnak előbb-utóbb ORM eszközről valamilyen más ADO.NET megoldásra. Kérdés hol a határ, amikor még megéri ORM eszközt használni?
Az szokásos üzleti alkalmazások esetén az esetek 90%-ára szerintem jó egy ORM, a maradék 10-et kell más módon megoldani.
Pár apró megjegyzés:
A második sorban a [Extent1].[LastName] IS NULL felesleges, hiszen ha a paraméter nem null, és egyenlő a LastName-mel, akkor a LastName sem lehet NULL. Persze ettől az execution plan nem változik.
Az is érdekes, hogy a 2008-as SQL nem rontja így el.
Viszont ami ennek az egésznek a nagyon nagy előnye lehetne, az a következő:
using (var e = new AdventureWorks2012Entities()) { e.Configuration.UseDatabaseNullSemantics = true; var matthew = "Matthew"; IQueryable query = e.Person; if (matthew == null) query = query.Where(p => p.LastName == null); else query = query.Where(p => p.LastName == matthew); query.FirstOrDefault(); }Valahogy számomra annak van varázsa, ha minden logika a c# kódban van, és nem kell SQL scripteket release-elni, ha bármit változtatni kell.
Ákos: kipróbáltad SQL 2008-ban, és azonos a két plan? Ha az AdventureWorksön futtattad, akkor vigyázz, mert alapban not nullos a FirstName és a LastName, én módosítottam őket nullossá.
A példát nem így gondoltad?
using (var e = new AdventureWorks2012Entities()) { var matthew = “Matthew”; IQueryable<Person> query = e.Person; if (matthew == null) e.Configuration.UseDatabaseNullSemantics = false; query = query.Where(p => p.LastName == null); else e.Configuration.UseDatabaseNullSemantics = true; query = query.Where(p => p.LastName == matthew); query.FirstOrDefault(); }Igazad van, ha NULL -osra módosítom, akkor elromlik a 2008-ason is.
Megmondom őszintén, nem próbáltam ki a kódot, amit beírtam, csak azt szerettem volna szemléltetni, hogy az egésznek nagy előnye, hogy viszonylag kényelmesen tudsz többféle query-t építeni a paraméterektől függően.
Wow kiszedte a < meg > az IQueryable mögül :)
Szóval az IQueryable<Person> akart lenni
Javítottam, sőt még be is színeztem neked. :)
A dinamikusan komponálhatóság óriási előnye az ORM-nek, illetve annak a ténynek, hogy ő egy SQL generátor.
Pl. amikor keresni kell sokféle dologra, aminek csak egy része van megadva, akkor ezzel csak az kerül be a where-be, ami kell, így nagyon optimális tud lenni a lekérdezés.
“Igazad van, ha NULL -osra módosítom, akkor elromlik a 2008-ason is.”
Ebből látszik, az SQL Server optimizer felhasználja azt az infót is, hogy egy oszlop nullos-e? Illetve azt is, ha van rajta unique index. Okos jószág, és még okosabb lett 2014-ben. Már írom róla a cikket…
@Soci mar alig varjuk a cikket :-)
Gyuri, mire gondolsz?
Ja, SQL 2014. A memtables már folyamatban van, de veszett sok dolgot akarok írni, asszem felbontom több részre, így az első rész már ma kimehet.