A Table Valued Function-öknél eddig nem lehetett megadni információt a szervernek a függvényből jövő adatok sorrendjére, így hiába jöttek sorban az adatok, ha a TVF-ből jövő lekérdezés eredményét sorrendeztettük order by-jal, akkor az SQL Server újrarendezte az adatokat, ami meglehetősen nagy költséggel járhat. 2008-ban már megjelölhető az adatok előrendezettsége, ami jelentős költségmegtakarítást eredményezhet.
Nézzük pár példát!
Windows Event Log publikálás:
using System.Collections;
using System.Data.SqlTypes;
using System.Diagnostics;
using Microsoft.SqlServer.Server;
public class TVF
{
[SqlFunction(FillRowMethodName = "FillEventLogRow")]
public static IEnumerable EventLog(SqlString logName)
{
if (logName.IsNull)
{
return new int[0];
}
else
{
return new EventLog(logName.Value).Entries;
}
}
public static void FillEventLogRow(object obj,
out SqlDateTime timeWritten,
out SqlString message,
out SqlString category,
out SqlString source,
out SqlInt64 eventId)
{
EventLogEntry e = (EventLogEntry)obj;
message = new SqlString(e.Message);
timeWritten = new SqlDateTime(e.TimeWritten);
category = new SqlString(e.Category);
source = new SqlString(e.Source);
eventId = new SqlInt64(e.InstanceId);
}
}
use AdventureWorks;
go
--Kell az external_access-hez
alter database AdventureWorks set trustworthy on
go
exec sp_configure 'clr enabled', '1';
reconfigure with override;
go
if object_id('EventLog') is not null drop function EventLog
if exists(select * from sys.assemblies where name = 'SqlClrTest') drop assembly SqlClrTest
create assembly SqlClrTest from 'C:\sql2008\SqlClrTest\bin\SqlClrTest.dll'
with permission_set = external_access
go
--Létrehozzuk a tábla kimenetű függvényt,
--ami az eventlogot publikálja ki
create function EventLog(@logname nvarchar(100))
returns table
(
Time datetime,
Message nvarchar(max),
Category nvarchar(max),
Source nvarchar(max),
EventId bigint
)
as external name SqlClrTest.TVF.EventLog
go
create function EventLogWithOrder(@logname nvarchar(100))
returns table
(
Time datetime,
Message nvarchar(max),
Category nvarchar(max),
Source nvarchar(max),
EventId bigint
)
order (Time asc) --itt az újdonság
as external name SqlClrTest.TVF.EventLog
go
Látható, hogy az függvény létrehozásakor meg lehet adni, az adatok milyen sorrendben fognak jönni.
Ha hazudunk a sorrendet illetően, akkor lekérdezéskor így járunk:
Msg 5332, Level 16, State 1, Line 2
The order of the data in the stream does not conform to the ORDER hint specified for the CLR TVF ‘dbo.EventLog’. The order of the data must match the order specified in the ORDER hint for a CLR TVF. Update the ORDER hint to reflect the order in which the input data is ordered, or update the CLR TVF to match the order specified by the ORDER hint.
Én az event loggal jártam így. Elvileg az event log idő szerint sorba van rendezve. Gyakorlatilag azonban amikor az os-t telepítettem, akkor az alapértelmezett -8 órás időzóna volt megadva, amit telepítés után állítottam át. Ettől az idő is visszaállt 9 órával, így az event log elején voltak nem időrendi bejegyzések.
Miért jó megadni a sorrendet? Vessük össze ezt a két lekérdezést és a végrehajtási tervüket:
select * from dbo.EventLog(N'Application') order by Time select * from dbo.EventLogWithOrder(N'Application') order by Time

A valódi költség persze nem feltétlen így oszlik meg, de biztos jól mérhető a hatás.
Észrevette mindenki az Assert operátort? Ő a hazugságvizsgáló, ő veszi észre, ha mégse jó a beígért sorrend.
A következő példában az eredmények nagyon gyorsan generálódnak, így jobban látszik a rendezés költsége. Egy egyszerű hatványozó, kamatos-kamat számító függvényt mutatok:
[SqlFunction(FillRowMethodName = "FillAustinPowersRow")]
public static IEnumerable AustinPowers(SqlDouble baseNumber, SqlDouble power, SqlInt32 first, SqlInt32 last)
{
if (baseNumber.IsNull || power.IsNull || first.IsNull || last.IsNull)
{
return null;
}
if (first < 0)
{
throw new ArgumentOutOfRangeException("first",
"A sorozat első eleme min. 0 kell legyen.");
}
if (first > last)
{
throw new ArgumentOutOfRangeException("first, last",
"A sorozat első elemének kisebb vagy egyenlő sorszámúnak kell lenni a utolsó elemnél.");
}
return AustinPowersWorker(baseNumber.Value, power.Value, first.Value, last.Value);
}
static IEnumerable AustinPowersWorker(double baseNumber, double power, int first, int last)
{
double curr = baseNumber * Math.Pow(power, first);
yield return curr;
for (int i = first; i < last; i++)
{
curr *= power;
yield return curr;
}
}
public static void FillAustinPowersRow(object obj, out SqlDouble num)
{
num = new SqlDouble((double)obj);
}
[/source]
Hát nem imádni való ez a yield?
[source='sql']
create function Austin(@base float, @power float, @first int, @last int)
returns table
(
power float
)
as external name SqlClrTest.TVF.AustinPowers
go
create function Austin2(@base float, @power float, @first int, @last int)
returns table
(
power float
)
order (power asc)
as external name SqlClrTest.TVF.AustinPowers
go
[/source]
Tesztek:
[source='sql']
select power from dbo.Austin2(4000000, 1.001, 0, 100000)
order by power
go
select power from dbo.Austin(4000000, 1.001, 0, 100000)
order by power
[/source]
Végrehajtási idők: 26000ms vs. 200ms. Ez már jelentős. Ráadásul, ha nem számok jönnek ki a TVF-ből, hanem pl. stringek, akkor a rendezés még sokkal költségesebb. (A méréseknél kikapcsoltam az eredmények megjelenítését a Management Studioban, hogy annak az ideje lehetőleg ne látsszon a kimenetben.)
Ami viszont furcsa, hogy kb. 10 futtatásból egyszer lefut pár 100 ms alatt az első függvény is. Nem tudom, mi lehet az oka.
A következő példa fájlokat listáz egy könyvtárban, amely listát elvileg az NTFS rendezetten ad vissza:
[source='csharp']
[SqlFunction(FillRowMethodName = "FillDirListRow")]
public static IEnumerable DirList(SqlString startDir)
{
if (startDir.IsNull)
{
return null;
}
return Directory.GetFiles(startDir.Value);
}
public static void FillDirListRow(object obj, out SqlString fileName)
{
fileName = new SqlString((string)obj);
}
[/source]
[source='sql']
create function DirList(@base nvarchar(300))
returns table
(
FileName nvarchar(300)
)
order (FileName asc)
as external name SqlClrTest.TVF.DirList
go
select * from dbo.DirList('c:\windows\system32')
[/source]
Nos, elküldenek a náthás frászba, hogy már megint beígértem egy sorrendet, de nem tartottam be. No, mondom, ez érdekes lesz, ezek szerint mégse rendezetten adja vissza a neveket az NTFS? Nézzük a bibis váltást:
[source='c']
11/02/2006 01:34 PM 6,656 blbres.dll
11/02/2006 01:34 PM 17,408 blb_ps.dll
[/source]
Hoppá, igaza van, ez tényleg nem stimmel. WTF? Némi guglizás után fény derült a titokra.
<a href="http://blogs.msdn.com/oldnewthing/archive/2005/06/17/430194.aspx">Why do NTFS and Explorer disagree on filename sorting?</a>
<a href="http://blogs.msdn.com/michkap/archive/2005/01/16/353873.aspx">How [case-]insensitive (apologies to Frank Sinatra)</a>
Az első linken Raymond Chen barátunk elmondja, hogy az NTFS nem a mi örömünkre rendez, hanem a saját hatékonysága érdekében, így ne is várjuk tőle, hogy majd mindenféle nyelvi szabályok szerint rendezze a kimenetet, rendezi, ahogy neki jó. Amikor leformázzuk a kötetet, akkor kialakul egy sorrend, amit aztán semmiféle locale váltás már nem befolyásol. Szóval esetünkben más az SQL Server által elvárt sorrend, mint amelyet az NTFS használ rendezéshez. Ok, az NTFS fekete doboz, de milyen sorrendben gondolkodik az SQL Server ebben az esetben? Másképpen fogalmazva, mi a TFV-ünk egyetlen oszlopának a COLLATION-je?
A <a href="http://msdn2.microsoft.com/en-us/library/ms179886.aspx">doksi</a> alapján Coercible-default, azaz "... If the object is declared in a batch, the object is assigned the default collation of the current database for the connection.". Ez vonatkozik ránk. Az adatbázis SQL_Latin1_General_CP1_CI_AS collation-ű, ez az AdventureWorks alapértelmezett elmebeteg collation-je.
Hogyan lehetne más collation-t rámondani a TFV kimenetére? Mi sem egyszerűbb:
[source='sql']
create function DirList(@base nvarchar(300))
returns table
(
FileName nvarchar(300) collate Latin1_General_CI_AS
)
order (FileName asc)
as external name SqlClrTest.TVF.DirList
Ettől nem lesz jó a függvényünk, de látjuk, hogyan lehet collation-t megadni az oszlop definícióban. :)
A kis-nagybetű mappelés az NTFS-ben a $UpCase nevű system metadata file-ban tárolódik, ha valaki megmutatja, hogyan kell ezt olvasni, megpróbálom kitalálni, van-e hozzá illő collation a szerverben.
Összegezve: ha a TVF által publikált adatok elve valamilyen sorrend szerint vannak rendezve, akkor ezt a rendezettséget kommunikálhatjuk az SQL Server 2008 felé, így a rendezéseket, csoportosításokat vagy a distinct műveleteket jelentősen gyorsíthatjuk.
Emellett (nem trviális és kevésbé ismert infó), ha egy táblába szúrjuk be a TVF-ből kiszelektált adatokat, és a a céltábla clu indexet tartalmaz, ami pont a TVF kimenetének megfelelő sorrendet ír elő, akkor sokkal gyorsabb lesz az insert. Erről már írtam egyszer.
De, hogy itt is lássuk a hatást:
if object_id('tempdb..#Powers') is not null drop table #Powers
create table #Powers
(
id int not null identity,
power float not null
)
create clustered index idx1 on #Powers(power);
go
insert #Powers
select power from dbo.Austin2(4000000, 1.001, 0, 100000)
option (recompile)
insert #Powers
select power from dbo.Austin(4000000, 1.001, 0, 100000)
option (recompile)
A tábla pont úgy van rendezve a clu index miatt, mint a TVF kimente. Emiatt a két insert végrehajtási terve is más lesz:
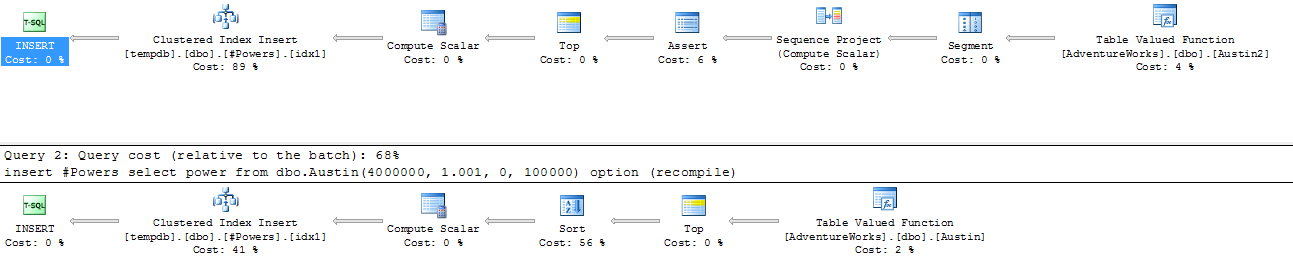
Durva, mi? A Sort visz el igen jelentős költségeket. Konkrétan, a példabeli százezer sor esetén 12.1 vs. 16.7 mp. Az elsőnél a CPU 5.4mp, a másodiknál 8mp volt. De ami nagyon fontos, és ez nem látszik a profiler kimenetben, kutya sok memória kell a sorbarendezéshez, ezért többször el is szállt hibával a második insert, hogy adott időn belül nem tudott memóriát kapni.
Msg 8645, Level 17, State 1, Line 1
A timeout occurred while waiting for memory resources to execute the query in resource pool ‘default’ (2). Rerun the query.
Egy szó mint száz, becsüljétek meg az eleve rendezett adatokat. :)
Ps. Az előbbi timeoutról infó, akit érdekel.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.