A memóriatáblákhoz kötelező minimum 1 indexet létrehozni, és ez az index egy hash index kell legyen. Mivel kötelező rajtuk egy primary key is, ezért az első indexen nem kell sokat gondolkodni, az a pk mögötti index lesz.
A hash index hasonló mint a .NET Dictionary vagy bármely más rendszer hash táblája. Az index értékekből hasht képeznek, az azonos hash-ű sorokat összeláncolják pointerek mentén. Az adatok NEM lapokon vannak elhelyezve, mivel a lapok a diszk adatok miatt voltak kialakítva a normál táblák esetén. Mivel nincsenek lapok, nem veszekednek a szálak a lapok latch-elésén se (mint a .NET lock kulcsszó), így sokkal nagyobb párhuzamosságot érnek el, mint a korábbi struktúra esetén. Diszk tábláknál ha egy lapon sokan matatnak egyszerre, be kell várják egymást. Itt minden sor szinten van tárolva, azaz sokkal finomabb felbontású régiókat kell védeni, ráadásul a módosítás sose helyben történik, de erről majd a konkurenciáról szóló részben írok.
Nincsenek GAM, SGAM, PFS, IAM és más egyéb szokásos adatösszetartó lapok, csakis az indexek tartják egyben egy tábla sorait. Ezért kell minimum 1 index a táblára.
További indexeket is létre lehet hozni, összesen max. 8-at. Azért ennyit, mert az ütköző hash-ek miatt össze kell láncolni a sorokat, így minden sorba be van építve fixen hash index számú pointer a láncoláshoz, de be kellett határolni a számukat, ne fogjanak el túl sok helyet. Így néz ki egy sor, a végén vannak a láncolt listákhoz a pointerek :
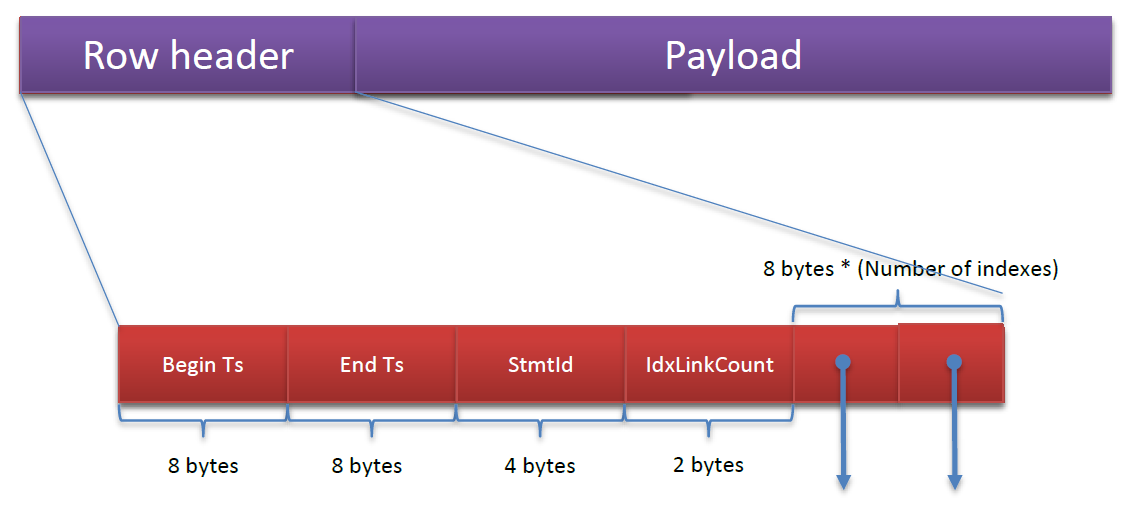
Az első mezőkről majd a párhuzamosság kezeléséről (concurrency) szóló részben írok.
A hash indexnél fontos a BUCKET_COUNT, ez szabályozza mennyire szórjon a hash függvény. Ha túl kicsire vesszük, hosszú láncolt listák alakulnak ki egy bucketen belül. Ha túl nagy, feleslegesen eszi a memóriát, és lassítja a scaneket, mivel minden bucketet végig kell néznie scan során. Mivel 64 biten dolgozunk, egy pointer 8 byte, így hash index mérete BUCKET_COUNT * 8 byte, csak mindig a legközelebbi, 2 hatványra kerekítik belülről. Azaz 1000-et megadva 1024 vödör keletkeze, ami 8192 byte (ez persze a gyakorlatban nagyon pici lenne, nem lenne hatékony index). Érdemes akkorára venni, mint ahány különböző értéke van a kulcsnak * 1-2. Érhető, hisz így nem nagyon lesz sokelemű a láncolt lista egy bucketen belül, kevés lesz az ütközés.
Primary keynél könnyű a helyzet, mivel egyedi értékeket tartalmaz. Ha a tábla például 3 millió sort tartalmaz, és várhatóan a közeljövőben se nő mondjuk 5 millió fölé, akkor egy hasonló nagyságrendű BUCKET_COUNT jó lehet. Később, ha sokkal több sor lesz, majd újra létrehozzuk a táblát más BUCKET_COUNT-tal. Ebből látszik, hogy a normál táblákkal szemben itt nem annyira önhangoló minden, mint megszoktuk.
Normál oszlopoknál egy select count(distinct oszlop) lekérdezéssel könnyű megnézni, mennyi egyedi érték van a táblában. Ha mondjuk 100 különböző érték van egy 5000 soros táblában, akkor egy nagy BUCKET_COUNT esetén is csak 100 bucketben lesz érték, azaz a bucketekben átlagban 50 sor lesz, amiben már csak lineárisan lehet keresni. Magyarul, erre nem jó a hash index, ide sima fa alapú indexre lesz szükség, mivel azt is létre lehet hozni a memória táblákon.
Nézzük meg a gyakorlatban!
Hozzunk létre egy memória táblát az AdventureWorks Person táblája adataival:
CREATE TABLE [Person].[Person_InMem]
(
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[NameStyle] [bit] NOT NULL CONSTRAINT [DF_Person_InMem_NameStyle] DEFAULT ((0)),
[Title] [nvarchar](8) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[FirstName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[MiddleName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[LastName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[Suffix] [nvarchar](10) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[EmailPromotion] [int] NOT NULL CONSTRAINT [DF_Person_InMem_EmailPromotion] DEFAULT ((0)),
[rowguid] [uniqueidentifier] NOT NULL CONSTRAINT [DF_Person_InMem_rowguid] DEFAULT (newid()),
[ModifiedDate] [datetime] NOT NULL CONSTRAINT [DF_Person_InMem_ModifiedDate] DEFAULT (getdate()),
CONSTRAINT [PK_Person_InMem_BusinessEntityID] PRIMARY KEY NONCLUSTERED HASH
(
[BusinessEntityID]
)WITH ( BUCKET_COUNT = 1000)
)WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GO
INSERT INTO [Person].[Person_InMem]
([BusinessEntityID]
,[PersonType]
,[NameStyle]
,[Title]
,[FirstName]
,[MiddleName]
,[LastName]
,[Suffix]
,[EmailPromotion]
,[rowguid]
,[ModifiedDate])
SELECT [BusinessEntityID]
,[PersonType]
,[NameStyle]
,[Title]
,[FirstName]
,[MiddleName]
,[LastName]
,[Suffix]
,[EmailPromotion]
,[rowguid]
,[ModifiedDate]
FROM [Person].[Person]
Az eredeti táblából kihagytam az xml oszlopokat, azok nem támogatottak memória táblákban. Hash bucket számosságnak 1000-et adtam meg. A táblában 19972 sor van. Mivel primary key-ről van szó, ugyanennyi különböző érték van benne. De csak 1024 bucketünk van, azért átlagosan kb. 20 sor kerül egy bucketbe. Nézzük meg, igaz-e az elmélet, az új dm_db_xtp_hash_index_stats nézettel:
SELECT object_name(hs.object_id) AS 'object name', i.name as 'index name', hs.total_bucket_count, hs.empty_bucket_count, floor((cast(empty_bucket_count as float)/total_bucket_count) * 100) AS 'empty_bucket_percent', hs.avg_chain_length, hs.max_chain_length FROM sys.dm_db_xtp_hash_index_stats AS hs JOIN sys.indexes AS i ON hs.object_id=i.object_id AND hs.index_id=i.index_id where object_name(hs.object_id) = 'Person_InMem'
object name index name total_bucket_count empty_bucket_count empty_bucket_percent avg_chain_length max_chain_length -------------- --------------------------------- -------------------- -------------------- ---------------------- -------------------- -------------------- Person_InMem PK_Person_InMem_BusinessEntityID 1024 0 0 19 38
Látható, hogy az átlagos lánc hossza egy bucketben 19, de van legalább egy 38 hosszú is, mivel a hash függvény nem teljesen egyenletes.
Jó ez nekünk? Nagyon nem. Ideális esetben 1-2 tétel van csak egy bucketben, de 10 fölött már erősen érezhető lesz a teljesítményveszteség. Látható, hogy az üres bucketek (áttérek a vödör szóra, de elég hülyén hangzik) száma 0. Ez is probléma, “nincs hely” az új sorok részére, azaz még nagyobb torlódás lesz később. Az útmutató szerint az üres vödrök száma legalább 33% kell legyen, hogy legyen hely a táblának növekedni.
Próbáljuk meg magasabbra venni a vödrök számát, mondjuk 10000-re. Mivel memória tábláknál nincs alter table, újra létre kell hozni, más paraméterekkel, majd újratölteni. Ez után a hash statisztikák:
object name index name total_bucket_count empty_bucket_count empty_bucket_percent avg_chain_length max_chain_length -------------- --------------------------------- -------------------- ------------------- ---------------------- -------------------- -------------------- Person_InMem PK_Person_InMem_BusinessEntityID 16384 4933 30 1 8
Na, ez már sokkal jobban néz ki. 16384 vödör van (10000 után ez volt a következő 2 hatvány), 30%-a a vödröknek üres, átlagosan 1 elem van minden vödörben (nyilván kicsit több, mivel 19000 sor van 16000 vödörre).
De nem mindig lehet csak a vödrök számával ilyen szép helyzetet előállítani, ha túl sok ismétlődés van az adatokban. Hozzunk létre egy második indexet is, ezúttal a FirstName oszlopra:
SELECT count(distinct FirstName) FROM [AdventureWorks2012].[Person].[Person]; --1018 CREATE TABLE [Person].[Person_InMem] ( [BusinessEntityID] [int] NOT NULL, [PersonType] [nchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [NameStyle] [bit] NOT NULL CONSTRAINT [DF_Person_InMem_NameStyle] DEFAULT ((0)), [Title] [nvarchar](8) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [FirstName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [MiddleName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [LastName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [Suffix] [nvarchar](10) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [EmailPromotion] [int] NOT NULL CONSTRAINT [DF_Person_InMem_EmailPromotion] DEFAULT ((0)), [rowguid] [uniqueidentifier] NOT NULL CONSTRAINT [DF_Person_InMem_rowguid] DEFAULT (newid()), [ModifiedDate] [datetime] NOT NULL CONSTRAINT [DF_Person_InMem_ModifiedDate] DEFAULT (getdate()), CONSTRAINT [PK_Person_InMem_BusinessEntityID] PRIMARY KEY NONCLUSTERED HASH ( [BusinessEntityID] )WITH ( BUCKET_COUNT = 10000) , INDEX [ix_FirstName] NONCLUSTERED HASH ( [FirstName] ) WITH ( BUCKET_COUNT = 1000) ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
De nem jön létre az index, mert:
Indexes on character columns that do not use a *_BIN2 collation are not supported with indexes on memory optimized tables.
Ez van, a hasht gyorsan kell tudni előállítani, ebben a verzióban legalábbis nem mentek bele, hogy a nyelvek nemzeti sajátosságait kihasználva is képezzenek hasht. Ezekre lehet majd rendes fa alapú indexet létrehozni, de most koncentráljunk még a hash indexekre.
Lássuk a dátum oszlopon:
SELECT count(distinct [ModifiedDate]) FROM [AdventureWorks2012].[Person].[Person] --1290 CREATE TABLE [Person].[Person_InMem] ( [BusinessEntityID] [int] NOT NULL, [PersonType] [nchar](2) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [NameStyle] [bit] NOT NULL CONSTRAINT [DF_Person_InMem_NameStyle] DEFAULT ((0)), [Title] [nvarchar](8) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [FirstName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [MiddleName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [LastName] [nvarchar](50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [Suffix] [nvarchar](10) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [EmailPromotion] [int] NOT NULL CONSTRAINT [DF_Person_InMem_EmailPromotion] DEFAULT ((0)), [rowguid] [uniqueidentifier] NOT NULL CONSTRAINT [DF_Person_InMem_rowguid] DEFAULT (newid()), [ModifiedDate] [datetime] NOT NULL CONSTRAINT [DF_Person_InMem_ModifiedDate] DEFAULT (getdate()), CONSTRAINT [PK_Person_InMem_BusinessEntityID] PRIMARY KEY NONCLUSTERED HASH ( [BusinessEntityID] )WITH ( BUCKET_COUNT = 10000) , INDEX [ix_ModifiedDate] NONCLUSTERED HASH ( [ModifiedDate] ) WITH ( BUCKET_COUNT = 1000) ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
Dátum oszlopra már megy a hash index.
A hash statisztikák:
object name index name total_bucket_count empty_bucket_count empty_bucket_percent avg_chain_length max_chain_length -------------- --------------- -------------------- ------------------- ---------------------- -------------------- -------------------- Person_InMem ix_ModifiedDate 1024 262 25 26 143
Csapnivalóak az eredmények. Bár van 25% szabadon, azaz a vödrök számát nem lőttük alá, mégis átlagosan 26 sor van egy vödörben. Miért? Mert minden dátum kb. 20-szor szerepel a kulcsban, nem elég egyedi az oszlop. Az ilyenekre nem igazán hatékony a hash index.
A következő részben megnézzük, hogyan tárolja és hogyan használja a hash indexeket az SQL Server.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.